1. 垃圾收集算法 类型
垃圾收集算法 类型 分为4类
- 标记-清除算法
- 复制算法
- 标记整理算法
- 分代收集算法
2. 标记-清除 算法
这是 垃圾收集算法中 最最基础的算法。
2.1 算法思想
算法分为两个阶段:
- 标记阶段:标记出所有需要回收的对象;
- 清除阶段:统一清除(回收)所有被标记的对象。
下面主要讲解标记阶段。标记阶段主要分为:(先进行可达性分析)
- 第一次标记 & 筛选
- 第二次标记 & 筛选
a. 可达性分析
略
b. 第一次标记 & 筛选
- 方式描述
对象 在 可达性分析中 被判断为不可达后,会被第一次标记 & 筛选
a. 不筛选 = 继续留在 ”即将回收“的集合里,准备被回收 b. 筛选 = 从 ”即将回收“的集合取出
- 筛选的标准
该对象是否有必要执行 finalize()方法
- 若有必要执行(人为设置),则筛选出来,进入下一阶段:第二次标记 & 筛选;
- 若没必要执行,判断该对象死亡,不筛选 并等待回收
当对象无 finalize()方法 或 finalize()已被虚拟机调用过,则视为“没必要执行”
c. 第二次标记 & 筛选
当对象经过了第一次的标记 & 筛选,会被进行第二次标记,并被进行 筛选
- 方式描述
该对象会被放到一个 F-Queue 队列中,并由 虚拟机自动建立、优先级低的 Finalizer 线程去执行 队列中该对象的 finalize()
- finalize()只会被执行一次
- 但并不承诺等待finalize()运行结束。这是为了防止 finalize()执行缓慢 / 停止 使得 F-Queue队列其他对象永久等待。
- 判断标准
在执行finalize()过程中,若对象依然没与引用链上的GC Roots 直接关联 或 间接关联(即关联上与GC Roots 关联的对象),那么该对象将被判断死亡,不筛选(留在”即将回收“集合里) 并 等待回收
总结

2.2 优点
算法简单、实现简单
2.3 缺点
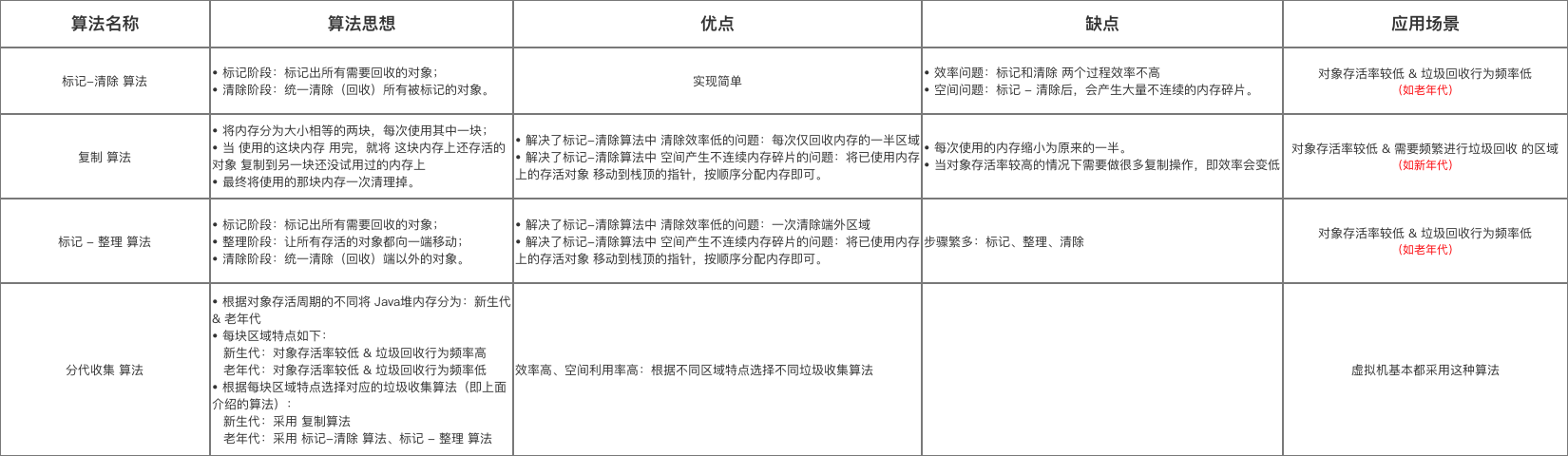
- 效率问题:即 标记和清除 两个过程效率不高
- 空间问题:标记 - 清除后,会产生大量不连续的内存碎片。
这导致 以后程序 需要分配较大空间对象时 无法找到足够大的连续内存 而被迫 触发另外一次垃圾收集行为,这导致非常浪费资源。
下面继续介绍的算法就是为了解决上述两个问题的。
2.4 应用场景
对象存活率较低 & 垃圾回收行为频率低 的场景
如老年代区域,因为老年代区域回收频次少、回收数量少,所以对于效率问题 & 空间问题不会很明显。
3. 复制算法
该算法的出现是为了解决 标记-清除算法中 效率 & 空间问题的。
3.1 算法思想
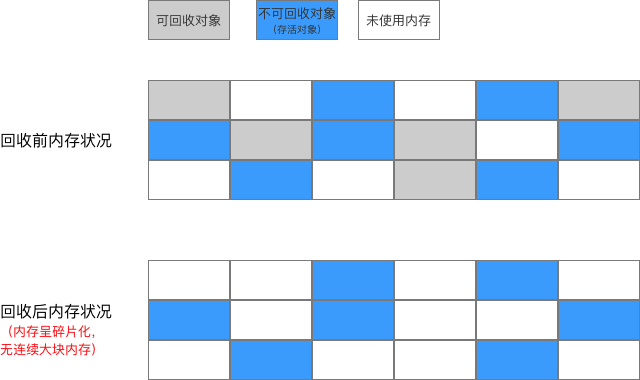
- 将内存分为大小相等的两块,每次使用其中一块;
- 当 使用的这块内存 用完,就将 这块内存上还存活的对象 复制到另一块还没试用过的内存上
- 最终将使用的那块内存一次清理掉。
3.2 优点
- 解决了标记-清除算法中 清除效率低的问题
每次仅回收内存的一半区域
- 解决了标记-清除算法中 空间产生不连续内存碎片的问题
将已使用内存上的存活对象 移动到栈顶的指针,按顺序分配内存即可。
3.3 缺点
- 每次使用的内存缩小为原来的一半。
- 当对象存活率较高的情况下需要做很多复制操作,即效率会变低
3.4 应用场景
对象存活率较低 & 需要频繁进行垃圾回收 的区域
如新生代区域
3.5 特别注意
a. 背景
新生代区域在进行垃圾回收时,98%对象都必须得回收
b. 问题
复制算法中 每次使用的内存缩小为原来的一半 利用率低 & 代价太高
c. 解决方案
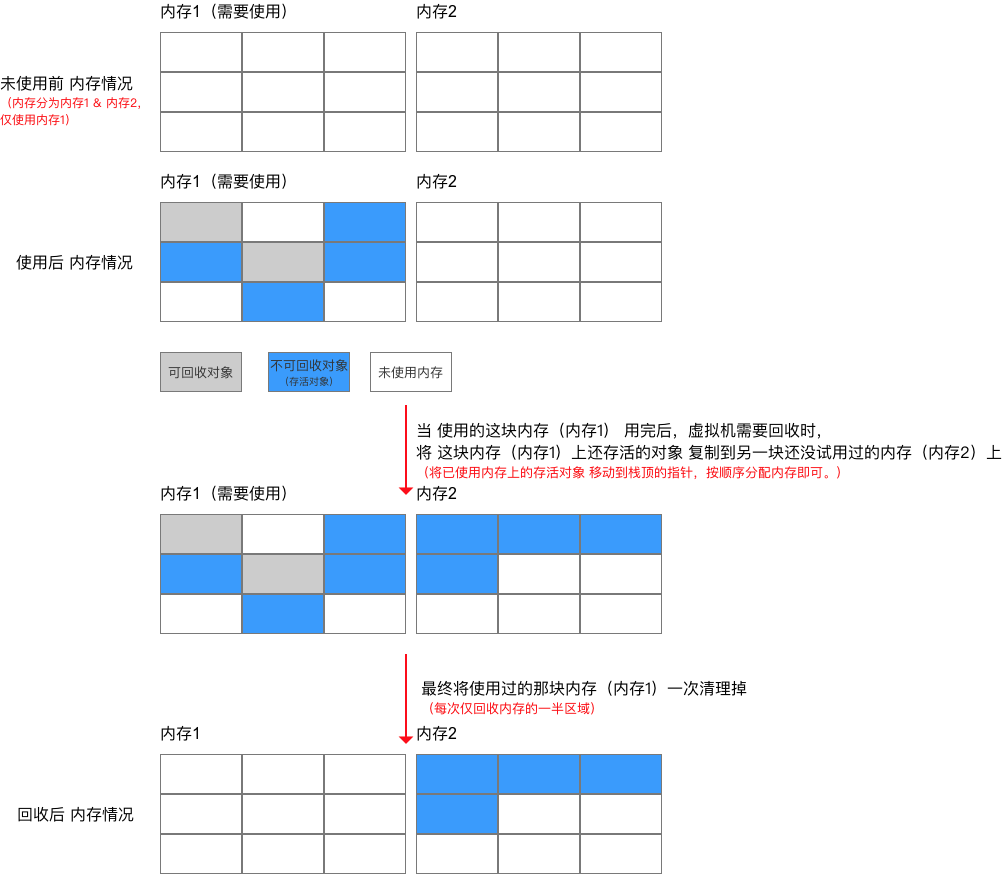
- 不 按 1:1的比例 划分内存,而是 按8:1:1比例 将内存划分为一块较大的 Eden 和两块较小的 Survivor 区域(From Survivor、To Survivor)
新生代内存区域划分
- 每次使用Eden、From Survivor区域;
- 用完后就 将上述两块区域存活的对象 复制到To Survivor区域上
- 最终一次清理掉Eden、From Survivor区域
使用逻辑 同 改进前
很多同学会问,假如 Eden、From Survivor区域上存活对象所需内存大小 > To Survivor区域怎么办?
解决方案:依赖老年代内存区域 做 内存分配担保。
即To Survivor区域 存不下来的对象 会通过 内存分配担保机制 暂时保存在老年代
4. 标记 - 整理 算法
此算法类似于第一种标记 - 清除 算法,只是在中间加多了一步:整理内存。
4.1 算法思路
算法分为三个阶段:
- 标记阶段:标记出所有需要回收的对象;
- 整理阶段:让所有存活的对象都向一端移动
- 清除阶段:统一清除(回收)端以外的对象。
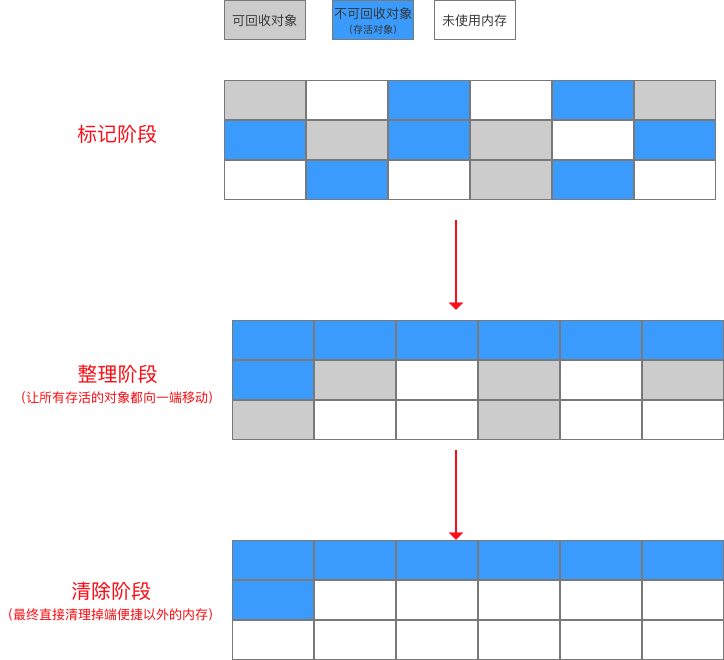
4.2 优点
- 解决了标记-清除算法中 清除效率低的问题:一次清楚端外区域
- 解决了标记-清除算法中 空间产生不连续内存碎片的问题:将已使用内存上的存活对象 移动到栈顶的指针,按顺序分配内存即可。
4.3 应用场景
对象存活率较低 & 垃圾回收行为频率低 的场景
如老年代区域,因为老年代区域回收频次少、回收数量少,所以对于效率问题 & 空间问题不会很明显。
5. 分代收集算法
主流的虚拟机基本都采用该算法,下面会着重讲解。
5.1 算法思路
- 根据 对象存活周期的不同 将 Java堆内存 分为:新生代 & 老年代 。分配比例如下:
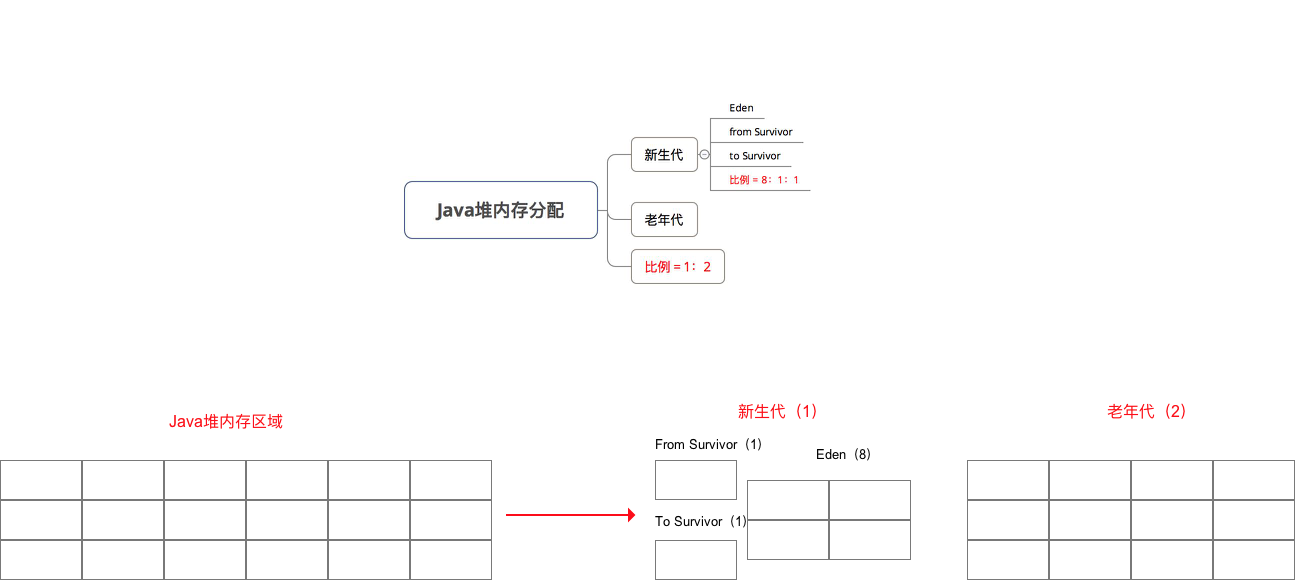
- 根据 两块区域特点 选择 对应的垃圾收集算法(即上面介绍的算法),具体细节请看下图

5.2 具体存储过程
- 新建的对象 一般会被优先分配到新生代的Eden区、From Survivor区
大对象(如很长的字符串以及数组)会直接分配到老年代,这是为了避免在 Eden 区 和 Survivor区之间发生大量的内存复制(因为新生代会采用复制算法进行垃圾收集)
- 这些对象经过第一次 Minor GC后,若仍然存活,将会被移到To Survivor区
一次清理掉Eden、From Survivor区域
- 在 To Survivor 区每经过一轮 Minor GC ,该对象的年龄就+1
- 当对象年龄达到一定时(阈值默认=15),就会被移动到老年代。
- 即新生代的对象在存活一定时间后,会被移动存储到老年代区域。
- 还有一种 新生代对象被移懂到老年代区域 的情况是:动态对象年龄判定。即如果在Survivor区中 所有相同年龄对象的大小总和 大于 Survivor区内存大小一半时,所有大于或等于该年龄的对象都会直接进入老年代。
特别注意
From Survivor 和 To Survivor之间会经常互换角色。
每次发生GC时,把Eden区和 From Survivor区中 存活且没超过年龄阈值的对象 复制到To Survivor区中(此时To Survivor变成了From Survivor),然后From Survivor清空(此时From Survivor变成了To Survivor)
5.2 优点
效率高、空间利用率高
根据不同区域特点 选择 不同的垃圾收集算法
5.3 应用场景
现在主流的虚拟机基本都采用 分代收集算法 ,即根据不同区域特点选择不同垃圾收集算法。
- 新生代 区域:采用 复制算法
- 老年代 区域:采用 标记-清除 算法、标记 - 整理 算法
6. 总结
用一张图总结上述4个垃圾收集算法